Introduction:
In today’s busy world, being efficient is important for everyone. Whether we are running a business or just trying to stay on top of things, finding ways to do things faster and easier is a big deal. One thing that can really help with this is using a tool called Databricks’ Automating File Arrival Triggers.
This tool basically helps us to handle new files or data without having to do it manually. It saves us time and makes sure we don’t get into trouble by accident. In this blog post, I’ll be explaining why these triggers are important and I’ll show how to set them up easy to understand.
Traditional File Management Methods:
Before getting into the new feature of Databricks’ new file arrival triggers first have to know about the traditional file management method and how we handle the incoming data for example, previously in the manual approach team members had to regularly check specific folders or emails to spot any newly arrived files. Once a new file is identified, manual processing will be started, involving tasks like opening the file, extracting data, and entering it into relevant systems or databases. However, manual processes open the door to human error, including the risk of overlooking new files, misinterpreting information, or making mistakes in data entry.
This manual approach consumes considerable time, especially as the volume of incoming files increases. As a result, employees find themselves spending more time on repetitive tasks that could be better utilized elsewhere. to avoid these drawbacks Databricks has introduced a new feature called Automating File Arrival Triggers.

Why Automated File Arrival Triggers?
It will streamline our workflow by simplifying the process of handling incoming files, reducing manual effort, and improving efficiency also saves time by automating the monitoring and processing of new file arrivals. and it will reduce the error by ensuring greater accuracy in data handling and processing.
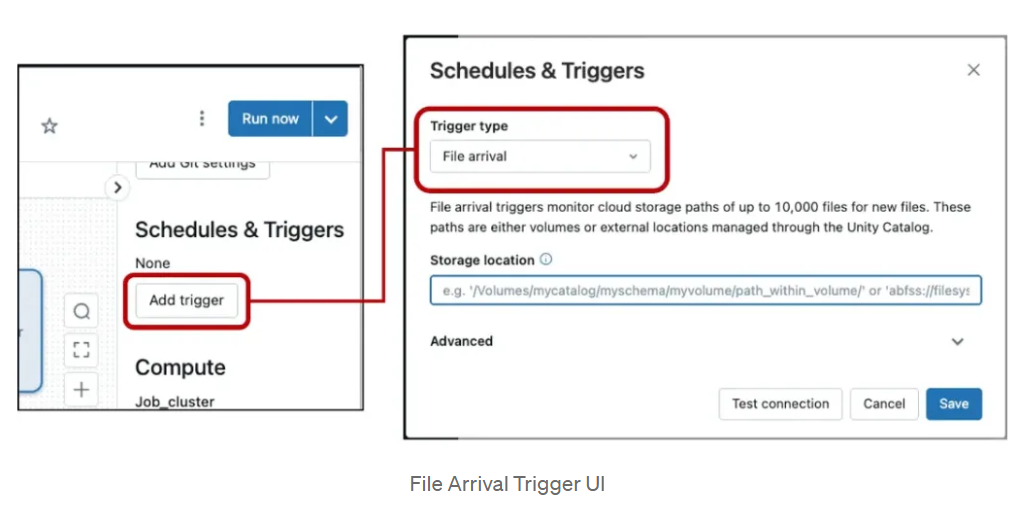
File Arrival Triggers in Databricks Workflows
File arrival triggers on Databricks start a job automatically when new files are found outside Databricks. File arrival triggers are especially helpful when scheduled jobs’ timing does not match up with the unpredictable arrival of new data.
Frequency: These new file arrival triggers are designed to check for new files at intervals of approximately one minute, when new data arrives, it is detected and processed quickly without much delay. This ensures that the system responds quickly to the incoming data, allowing us for timely processing and analysis.
Setup Requirements:
- Unity Catalog activation is necessary within our workspace.
- Usage of a storage location that is either a Unity Catalog volume or an external location integrated into the Unity Catalog metastore.
- Ensure READ permissions for the storage location and manage permissions for the job.
Limitations:
- A maximum of fifty jobs can be configured with a file arrival trigger.
- The designated storage location must contain fewer than 10,000 files.
- Similar restrictions apply to subpaths within external locations or volumes.
- It is advised to avoid utilizing paths associated with external tables or managed locations of catalogs and schemas.
How to Add a Trigger:
- Firstly, have to access the job details section within the Databricks UI.
- Click on “Add trigger” and select the “File arrival” option.
- Specify the desired storage location, whether it’s the root or a sub-path, to be monitored.
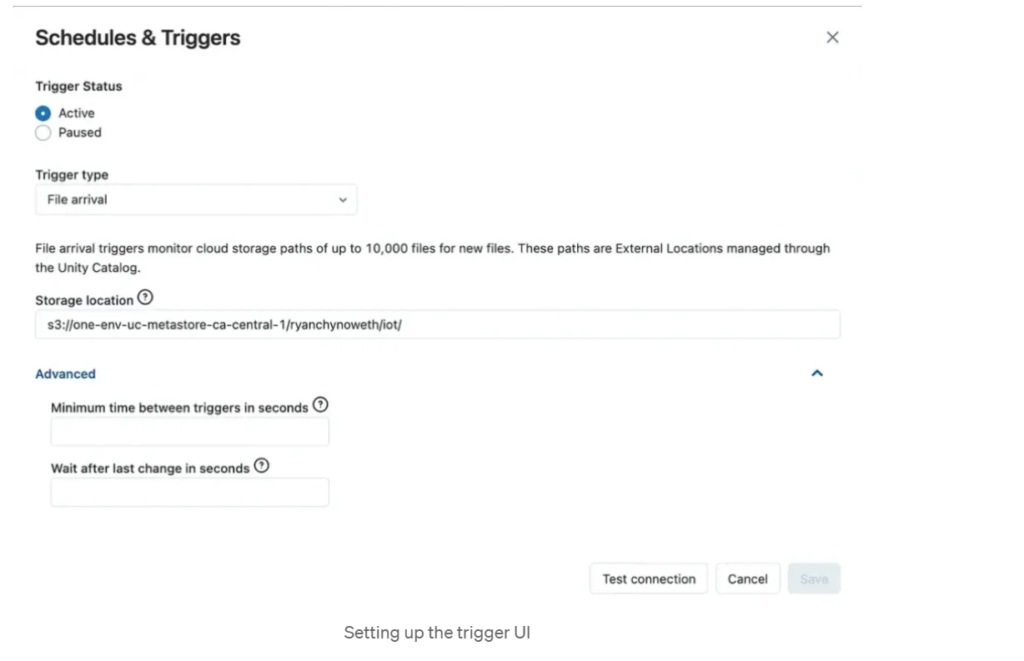
- Optionally configure advanced settings, such as defining the minimum time interval between triggers.
Demo Use case:
# Required Libraries
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
# Define External and Processed Locations
external_location = “abfss://demo@mystoragelocation.dfs.core.windows.net/file1/file_arival_trigger/source_location/”
processed_location = “abfss://target@mystoragelocation.dfs.core.windows.net/file1/file_arival_trigger/target_location”
boundry_location = “abfss://boundry@mystoragelocation.dfs.core.windows.net/file1/file_arival_trigger/boundry_location/”
# File Format
file_format = “csv”
# Defining the job code
def process_files():
# Fetch New File Paths
file_paths = [file.path for file in dbutils.fs.ls(external_location) if file.isFile()]
# Process Each File
for file_path in file_paths:
# Read and Apply Schema
df = spark.read.option(“delimiter”, “,”).option(“inferSchema”, “true”).option(“header”, “true”).csv(file_path)
# Write Processed Data
df.write.format(“delta”).mode(“append”).save(processed_location)
# Move Processed File
dbutils.fs.mv(file_path, file_path.replace(external_location, boundry_location))
# Print Success Message
print(f”File Processed: {file_path}”)
process_files()
To understand Databricks File Triggers better, practice the demo for the hands-on experience. And for more information check out the detailed documentation provided by Databricks.
Conclusion
Here I would conclude that using Databricks’ latest tool, file arrival triggers, is a great way to make business operations easier and more accurate. By following these steps in this blog, we can make our work more efficient and stay ahead in today’s competitive business world. Automation not only saves time and money but also sets the stage for future improvements and growth.
Author: Nihalataskeen Inayathulla