Introduction:
Organizations are generating more data than ever before in the data-driven world of today. It is harder for data teams to effectively manage, process, and evaluate this data as the volume of data increases.
Lakehouse, data management combines the advantages of data lakes with data warehouses. You can obtain quicker analysis and insights since we make it possible to handle both structured and unstructured data on a single platform with the aid of Lakehouse. When data is fed into a data lake, it is kept there in its raw format. Then, using a processing layer like Apache Spark, we convert and alter the data in real time, and it is then stored in a data warehouse that enables basic SQL queries. The Lakehouse design is becoming more and more popular for managing massive volumes of data due to its affordability and scalability.
To address this difficulty, many organizations are streamlining their analytics processes using contemporary data technologies like Databricks and DBT (Data Build Tool). In this blog, we’ll look at how DBT and Databricks can help organizations improve their analytics workflows.
Overview of DBT:
DBT is a well-liked open-source solution for managing data transformation and orchestration in modern data pipelines. DBT allows data teams can create models using the Jinja templating language to write complicated SQL-based transformations. Using standard development tools and methodologies, these models may subsequently be tested, deployed to production environments, and version controlled.
Additionally, DBT has several features that help data teams handle complex data transformation and orchestration processes. It is a popular option for modern data pipelines because of its modular architecture, dependency management, testing framework, and documentation tools.
Configuration Driven:
Through YAML files, the configuration-driven approach of DBT makes it easy to set up, manage, and maintain data pipelines. This strategy ensures consistency between projects while facilitating the simple creation and maintenance of complicated data pipelines.
Integration with Python, SQL, and Jinja:
DBT’s integration of Python, SQL, and Jinja enables the specification of data transformations using SQL, the expansion of functionality using Python, and the creation of reusable templates and macros using Jinja. Through this link, flexible data pipelines for different data sources and formats are made possible.
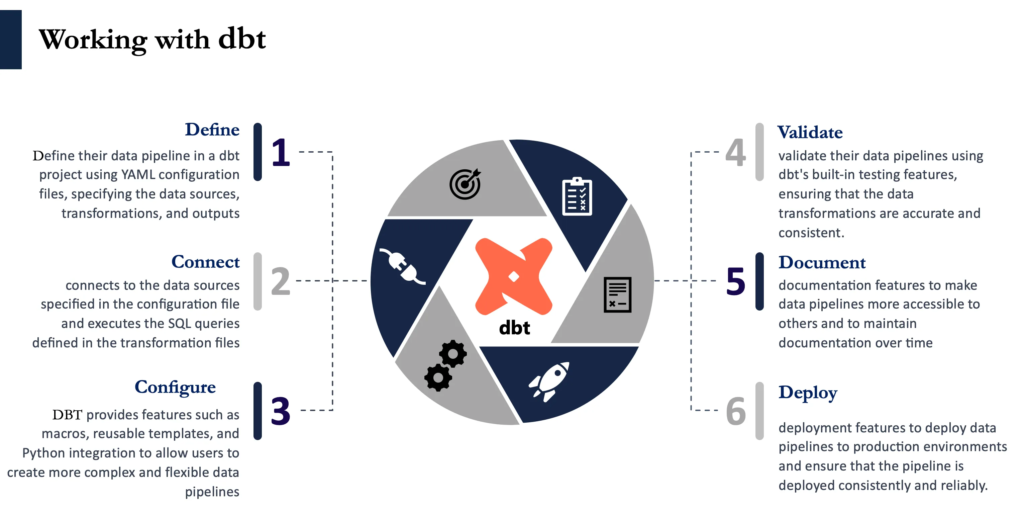
Incrementality and Modularity:
DBT provides incrementality and modularity to break the data pipeline into smaller pieces, making it simpler to test, maintain, and address problems. By restricting updates to the pipeline’s altered sections, this method saves time and labor.
Overview of Databricks:
A cloud-based platform for data engineering, data science, and analytics is called Databricks. Data teams can manage and analyze massive amounts of data using a variety of tools and technologies thanks to Databricks’ integrated analytics platform.
For data teams, Databricks offers a variety of features, such as:
Unified Data Analytics:
A unified platform for data engineering, data science, and analytics is provided by Databricks, allowing teams to communicate and operate more effectively.
Scalability:
Databricks offers a cloud-based platform that can grow to accommodate high workloads and massive amounts of data. Databricks SQL warehouse provides economic auto-scale workload for data analysis.
Governance:
Databricks offers thorough tools that can assist in implementing data governance on a complicated data platform. Databricks provides features like delta sharing and the unity catalog.
How Dbt with Databricks can Enhance Our Analytics Capabilities?
Organizations may streamline their analytics procedures in numerous ways by combining DBT with Databricks:
Streamlined Data Transformation and Orchestration:
Data teams may build complicated SQL-based transformations and arrange them into models using DBT, which streamlines data transformation and orchestration. Using common development tools and processes, these models may subsequently be tested, deployed to production environments, and version controlled. Data teams may simplify their data transformation and orchestration processes by utilizing DBT with Databricks, making it simpler to handle and evaluate massive amounts of data.
Scalability and Performance:
Databricks offer a cloud-based platform that can grow to manage heavy workloads and massive amounts of data. Organizations may use Databricks with DBT to streamline their analytics procedures by utilizing Databricks’ scalability and performance characteristics.
Collaboration and Efficiency:
Databricks offer a single platform for data engineering, data science, and analytics, enabling teams to work more cooperatively. Organizations may increase team communication and optimize their analytics procedures by utilizing Databricks with DBT.
Integrated Tools and Technologies:
Machine learning frameworks like TensorFlow and PyTorch are just a couple of the ones that Databricks interacts with. It also works with a wide variety of other tools and technologies, such as Spark, Python, SQL, and others. Organizations may use Databricks with DBT to optimize their analytics procedures by utilizing these linked tools and technologies.
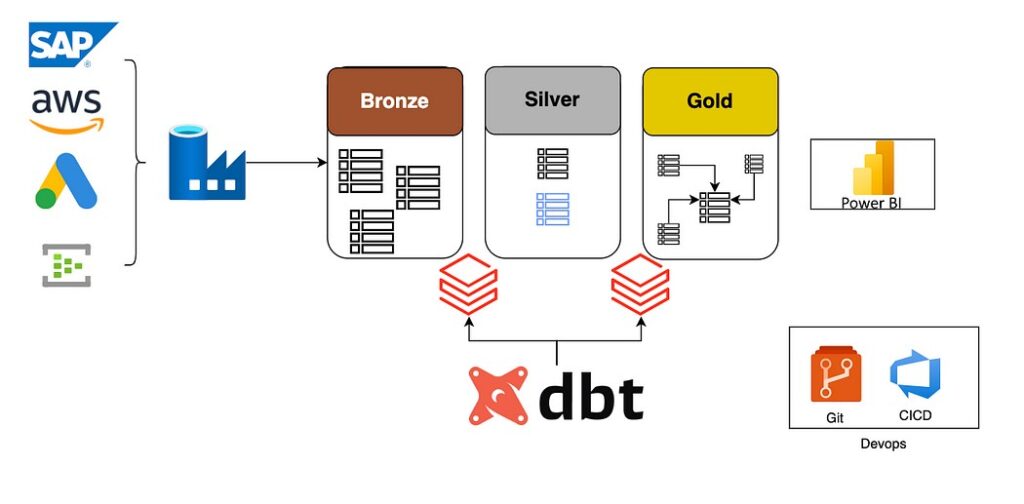
DBT and Databricks in Lakehouse Landscape:
In the Lakehouse ecosystem, Databricks and DBT are two essential technologies that work in tandem to offer a complete data platform for contemporary data pipelines. While Databricks offers a strong foundation for data processing and analysis, DBT offers a flexible and modular approach to data transformation. They support data governance, scalability, and effectiveness when used collectively.
Reusable data models may be developed using DBT and then delivered to Databricks for processing and analysis. While DBT offers capabilities like data lineage and metadata that help organizations understand where data originates from and how it has been altered, Databricks can be used to handle and evaluate enormous amounts of data. Overall, DBT and Databricks provide a powerful combination for implementing the Lakehouse architecture.
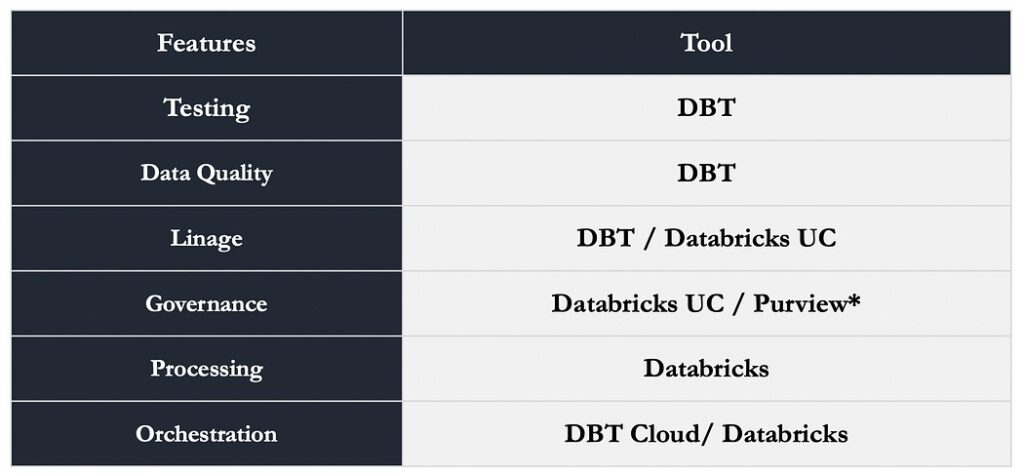
Responsibility Matrix in Lake House:
We can create standardization for different phases of the data and analytics lifecycle by integrating Databricks with dbt. The tools that may be utilized specifically for each step are highlighted in the accompanying matrix.
Conclusion:
Businesses have a wide range of options thanks to data mesh, including behavior modeling, analytics, and apps that employ a lot of data. The data mesh strategy’s concepts, techniques, and technologies are intended to fulfill some of the most important and unmet modernization goals for data-driven business efforts, even while they are not a panacea for centralized, monolithic data systems.
Author: Marketing