Introduction
Apache Spark has emerged as a powerful tool for big data processing, offering scalability and performance advantages. In the realm of PySpark, efficient data management becomes crucial, and three key strategies stand out: partitioning, bucketing, and z-ordering. In this blog post, we’ll delve into the concepts of partitioning, bucketing, and z-ordering, exploring how they enhance data processing capabilities in PySpark.
Partitioning in PySpark
Partitioning is a technique that involves dividing large datasets into smaller, more manageable parts. In PySpark, partitions are the basic units of parallelism, and organizing data into partitions can significantly improve performance. By distributing data across multiple partitions, Spark can execute operations in parallel, leveraging the full power of a cluster.
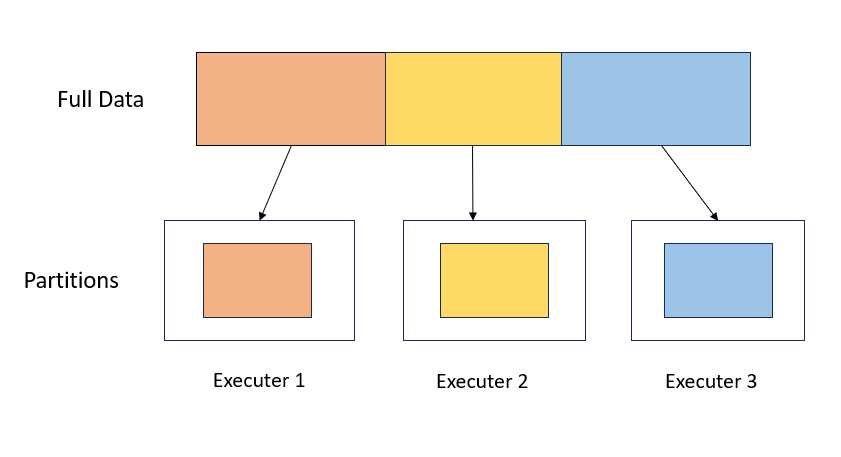
Why is Partitioning important?
- Load Balancing: Ensuring the equitable distribution of data across partitions optimizes cluster utilization, mitigating data skew and preventing uneven workload distribution among nodes.
- Network Optimization: A well-designed partitioning scheme minimizes network data transfer during transformations like join or groupByKey, enhancing execution speed by reducing unnecessary data shuffling.
- Parallelism: Optimizing partitions enables parallel and independent processing on diverse nodes, maximizing the cluster’s computational prowess.
Different Ways of Partitioning
1. Hash Partitioning:
Hash partitioning involves distributing data based on a hash function applied to a specific column. This ensures an even distribution of data across partitions. In PySpark, you can use the partitionBy method to specify the partitioning column:
df.write.partitionBy(“column_name”).parquet(“output_path”)
2. Range Partitioning:
Range partitioning involves dividing data into partitions based on specified ranges of column values. This is useful when you want to group similar values together. Here’s an example:
df.write.partitionBy(“column_name”).option(“range”, “1,10,20”).parquet(“output_path”)
Visual calculations support the utilization of numerous existing DAX functions. However, it’s important to note that, due to their operation within the visual matrix, functions dependent on model relationships, such as USERELATIONSHIP, RELATED, or RELATED TABLE, are not accessible in this context.
Bucketing in PySpark
What is Bucketing?
Bucketing is a technique that involves grouping data into fixed-size buckets or files based on hash functions. Each bucket is essentially a file, and data within the same bucket share the same hash value. This allows for more fine-grained control over data organization and can be particularly useful for certain types of queries.

Why is Bucketing important?
- Performance Improvement: Employing bucketing in Spark operations such as groupBy, join, and orderBy can notably enhance job efficiency, as it curtails output volumes and minimizes network shuffling during shuffle operations.
- Avoid Data Skew: Bucketing serves as a strategic tool in operations, aiding in the mitigation of data skew, thereby optimizing resource allocation for heightened efficiency in processing.
- Reduce Data Redundancy: By enabling Spark to selectively target subsets of data, bucketing circumvents the need for exhaustive scans, diminishing IO overhead and enhancing the efficiency of query execution for improved performance.
How to Implement Bucketing in PySpark?
To implement bucketing in PySpark, use the bucketBy method:
df.write.bucketBy(numBuckets, “column_name”).parquet(“output_path”)
Specify the number of buckets (numBuckets) and the column by which to bucket the data.
Z-Ordering in PySpark
The Key to Spatial Optimization:
Z-ordering, alternatively referred to as Z-Order Curve or Morton Order, stands as a spatial indexing technique designed to maintain spatial locality. When implemented in PySpark, Z-ordering proves useful for organizing columns in a way that ensures proximity of related data. This strategic arrangement becomes especially beneficial when conducting spatial queries, as it enhances the efficiency of retrieving and processing spatially correlated information.
Integrating Z-Ordering into PySpark:
df.write.option(“zOrderCol”, “column_name”).parquet(“output_path”)
Specify the column (column_name) to be used for Z-ordering, and PySpark will organize the data accordingly.
Let’s consider the below scenario.
We have 4 small files with fields id, name, and dept.
Since the size of the files is small we perform compaction. Now these 4 smaller files will be combined into two files.
Let’s query data and select the row where dept=ccc. Since the dept column is unordered and ccc values fall into the min and max range, both files will be read. So the data layout is not fully optimized yet.

Now along with compaction, let’s do z-ordering on the dept column.
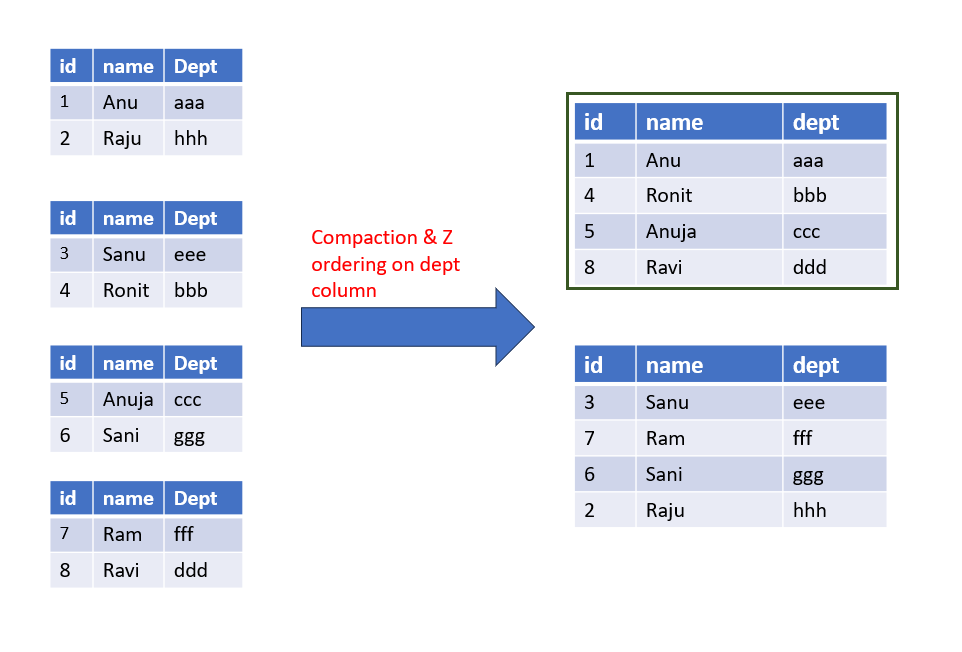
After compaction and Z-ordering the “dept” column, data is organized into two files. The first file spans “aaa” to “ddd,” while the second file covers “eee” to “hhh.” Notably, rows with “ccc” in the “dept” column are excluded from the second file due to range constraints.
While specifying column names in a list facilitates z-ordering across multiple columns, the efficacy diminishes with each additional column inclusion, impacting the optimization of data organization and retrieval.
Note:
Z-ordering, though essential, should be approached with caution, especially in resource-constrained environments or performance-sensitive applications. By recognizing the hidden costs of z-ordering and implementing optimization techniques, developers can strike a balance between visual richness and computational efficiency.

To conclude the article, while the strategies outlined herein offer avenues for enhancing Spark job performance, it’s crucial to recognize their nuanced trade-offs and varied outcomes contingent upon factors such as cluster setup, data characteristics, and job operations. Therefore, a discerning approach tailored to specific requirements ensures the optimal application of these strategies for maximal efficiency.
Author: Shilpa Joshi