In the fast-paced world of data analytics and machine learning, the ability to process and extract insights from massive datasets has become a critical necessity. Traditional methods often fall short when dealing with large-scale data, leading to bottlenecks and inefficiencies. This is where Apache Spark and Databricks come into play, providing a powerful combination of distributed computing and a collaborative platform for scalable machine learning.
Through the “Scalable Machine Learning with Apache PySpark” course by Databricks, valuable insights into the world of big data processing and machine learning at scale can be gained. This blog post aims to share an understanding of the key concepts and techniques learned, as well as the benefits of using Databricks for machine learning projects.
The Power of Apache Spark:
Apache Spark is an open-source, distributed computing framework that has revolutionized the way large-scale data processing is handled. At its core, Spark leverages in-memory computing, which significantly enhances performance compared to traditional disk-based systems. This efficiency is achieved by leveraging resilient distributed datasets (RDDs) and optimized data structures that allow for parallel processing across multiple nodes in a cluster.
One of the standout features of Spark is its ability to seamlessly integrate with a wide range of programming languages, including Python, R, Scala, and Java. This flexibility empowers data scientists and analysts to work within their preferred programming environments while still harnessing the power of distributed computing.
Databricks: A Collaborative Platform for Machine Learning:
Databricks is a unified analytics platform built on top of Apache Spark, designed to simplify and streamline the process of building and deploying machine learning models at scale. The platform provides a collaborative workspace where data scientists, engineers, and analysts can work together seamlessly, leveraging shared notebooks and integrated development environments (IDEs).
One of the key advantages of Databricks is its automation capabilities. It simplifies many of the tedious tasks associated with machine learning, such as feature engineering, model selection, data preprocessing, and hyperparameter tuning. This automation not only accelerates the development process but also ensures consistency and reproducibility across different projects and teams.
Scalable Machine Learning with Databricks:
The “Scalable Machine Learning with Apache PySpark” course by Databricks provides hands-on experience in implementing scalable machine learning pipelines using Apache Spark and Databricks. Here are some of the key concepts and techniques covered:
Distributed Data Processing:
Spark’s distributed computing capabilities allow for parallel processing of large datasets, enabling efficient data exploration, transformation, and feature engineering at scale.
Parallel Model Training:
By leveraging Spark’s distribution capabilities, Databricks enables parallel model training, significantly reducing the time required to train complex models on massive datasets.
Automated Machine Learning (AutoML):
Databricks’ AutoML features automate various steps in the machine learning workflow, such as feature selection, model selection, and hyperparameter tuning, accelerating the overall process, and improving model performance.
Model Deployment and Monitoring:
Databricks provides a streamlined process for deploying trained models as batch-scoring jobs or real-time web services, ensuring consistent and reliable model deployments. Additionally, it offers tools for model versioning, lifecycle management, and performance monitoring.
Collaboration and Reproducibility:
Databricks’ notebook-based interface promotes collaboration among team members, enabling easy sharing of code, visualizations, and results. This reproducibility ensures that machine learning pipelines can be easily replicated and validated across different environments.
Real-world Applications:
The course provides insights into various real-world applications of scalable machine learning with Databricks. Some notable examples include:
Predictive maintenance in the manufacturing industry, where sensor data from industrial machinery is analyzed to anticipate potential failures and plan proactive maintenance.
Fraud detection in the financial sector, where large volumes of transaction data are processed in real time to identify suspicious patterns and prevent fraudulent activities.
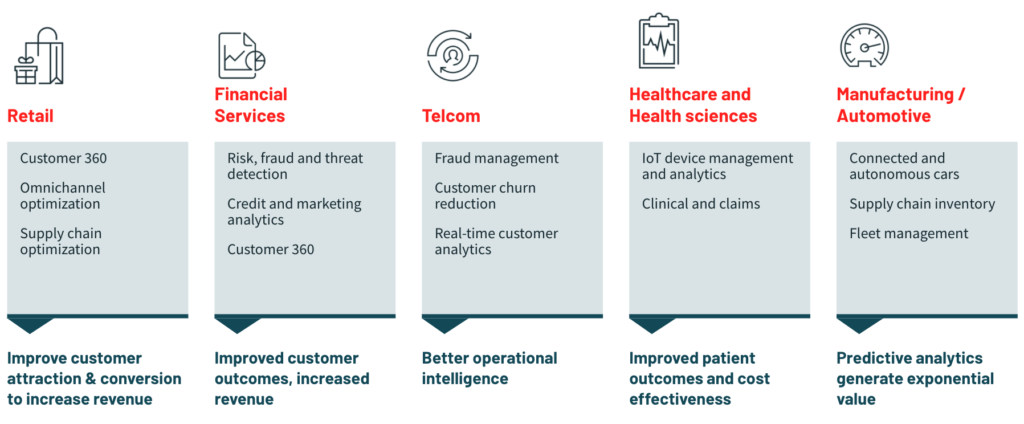
Personalized recommendations in the retail industry, where customer data is analyzed to provide tailored product recommendations, enhancing the customer experience, and driving sales.
Conclusion:
The “Scalable Machine Learning with Apache PySpark” course by Databricks has proven to be an eye-opening experience, equipping learners with the knowledge and skills to tackle complex machine-learning problems at scale. By leveraging the power of Apache Spark and the collaborative platform of Databricks, participants learn how to efficiently process large datasets, build robust machine learning models, and deploy them in production environments.
Explore Online Resources: Begin by exploring online resources and documentation provided by Apache Spark and Databricks. Familiarize yourself with the fundamental concepts of distributed computing, machine learning, and their integration with Spark.
Enroll in Courses: Consider enrolling in courses like the “Scalable Machine Learning with Apache PySpark” offered by Databricks. These courses provide structured learning paths, hands-on exercises, and expert guidance to deepen your understanding and practical skills in scalable machine learning.
Hands-on Practice: Practice is key to mastering any skill. Set up a Databricks account or leverage other cloud platforms offering Apache Spark environments. Experiment with building machine learning pipelines, processing large datasets, and deploying models.
Join Communities: Engage with communities and forums dedicated to Apache Spark and Databricks. Participate in discussions, seek advice, and learn from the experiences of others. Collaborating with peers can accelerate your learning journey and provide valuable insights.
Work on Projects: Undertake personal or collaborative projects to apply your newfound knowledge in real-world scenarios. Tackle challenges relevant to your interests or industry, such as predictive maintenance, fraud detection, or personalized recommendations.
Continuous Learning: Stay updated with the latest advancements in Apache Spark and Databricks. Attend webinars, conferences, and workshops to broaden your knowledge and stay ahead in the rapidly evolving field of scalable machine learning.
By following these steps and embracing a continuous learning mindset, you can embark on a rewarding journey towards mastering scalable machine learning with Apache Spark and Databricks, contributing to transformative advancements in data analytics and driving impactful outcomes across diverse industries.
Author: Rajesh S H
https://www.confluent.io/partner/databricks/